Méthodologie et Résultats de l’Expérience
Site cobaye : selimreggabi.com — Créé le 10/01/2026 — 0 autorité préalable
Comment Forcer Google à Indexer vos Pages
En 2026, forcer l’indexation d’une page est devenu relativement simple. Il existe deux approches : faire les choses proprement ou prendre des raccourcis.
Les Méthodes “Propres”
Ces méthodes respectent les guidelines Google :
1. Google Search Console (API Indexing)
La méthode officielle et la plus “propre” aux yeux de Google. Vous soumettez l’URL via l’interface ou l’API.
Mais attention : ça fonctionne parfois, parfois non. Tout dépend de la puissance du site, de ses antécédents, de sa thématique. Pour un nouveau site, l’indexation fonctionne facilement pour 4-5 pages. Au-delà, ça devient compliqué avec cette méthode seule, du moins à court terme.
2. Lien depuis un site Google News
C’est la méthode des professionnels. Nous avons plusieurs sites Google News dans notre réseau, voici ce qu’on observe :
- Site Google News très puissant : Vous pouvez mettre n’importe quoi, ça s’indexe, et Google vient crawler votre site dans la foulée
- Site Google News moyen : L’indexation fonctionne bien, mais le sujet doit être pertinent. Il faut utiliser les bonnes entités (Schema NewsArticle, mentions de sujets d’actualité)
- Exemple concret : Un article mentionnant le Venezuela ou son président s’indexe en moins de 3 minutes
Nous publierons prochainement un test en direct sur un de nos Google News pour démontrer cette méthode.
3. Flux RSS de sites à fort crawl
Certains sites sont crawlés toutes les minutes par Google. En plaçant votre lien dans leurs flux RSS, vous bénéficiez de leur fréquence de crawl.
Réalité : Fonctionne extrêmement bien sur les sites puissants. Sur les autres sites, c’est très aléatoire.
Les Raccourcis (Outils d’Indexation)
Ces outils automatisent le processus en soumettant vos URLs à de multiples sources :
| Outil | Statut |
|---|---|
| SpeedyIndex | ⚠️ En panne |
| Omega Indexer | ✅ Actif |
| Indexification | ✅ Actif |
| Colinkri | ✅ Actif |
| OneHourIndexing | ✅ Actif |
| Rapid Indexer | ✅ Actif |
| IndexMeNow | ✅ Actif |
Le verdict : Ils marchent tous, globalement. Par contre, leurs méthodes peuvent être “sales” : création de sous-domaines douteux, backlinks temporaires de mauvaise qualité, etc. À utiliser en connaissance de cause.
La Réalité de l’Indexation en 2026
Constat : L’indexation dépend entièrement de la puissance de votre site.
Sites sans autorité :
- Indexation difficile, parfois impossible sans forcer
- Les méthodes ci-dessus deviennent obligatoires
Sites avec autorité :
- Indexation plus facile, MAIS attention aux sujets
- Google a de la mémoire : il peut très bien indexer une catégorie facilement, et être difficile pour les autres
- Trop de thématiques différentes sans puissance associée = le site se casse sur le long terme
Indexation ≠ Classement
Même une fois indexée, une page sans :
- Contenu de valeur réelle
- Signaux d’engagement (clics, temps passé)
- Liens entrants de qualité
…sera désindexée en quelques semaines, voire quelques jours.
Forcer l’indexation est facile avec les bons outils. Rester dans l’index est le vrai défi. Et avec l’émergence des AI Overviews et des LLMs, l’enjeu n’est plus seulement d’être indexé mais d’être cité — un sujet que nous explorons en détail dans notre article sur l’AEO/GEO : le SEO à l’ère des agents IA.
Le Protocole Expérimental
Pourquoi ce site ?
Le domaine selimreggabi.com a été créé le 10 janvier 2026, spécifiquement pour cette expérience. Nous avions besoin d’un site :
- Sans aucune autorité préalable
- Jamais crawlé par Google auparavant
- Vierge de tout historique
Un site “puissant” aurait faussé les résultats : Google l’aurait crawlé naturellement en quelques heures. Avec un domaine neuf, chaque visite de Googlebot est directement attribuable à nos actions.
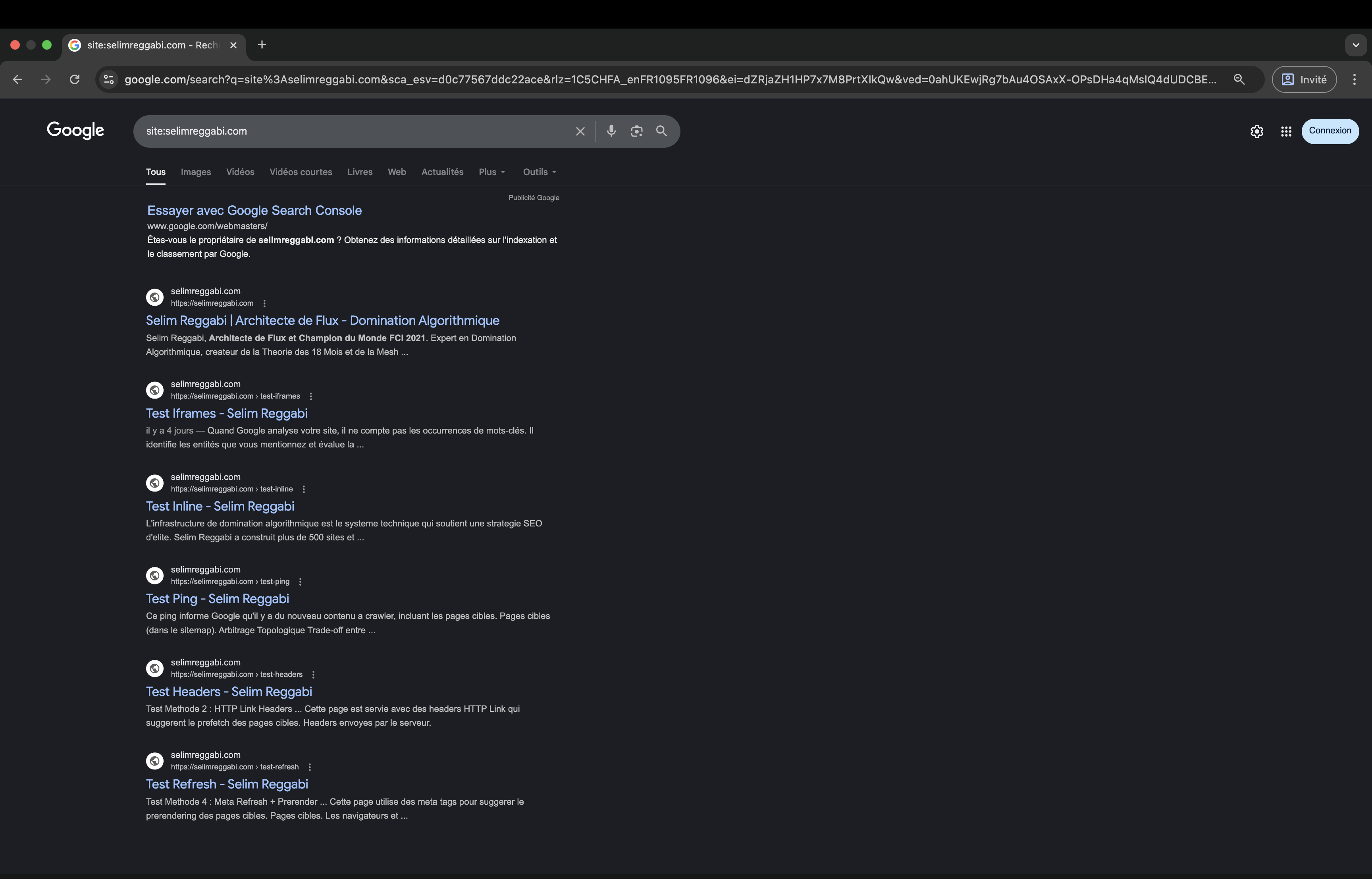 Capture d’écran du 11 janvier 2026 : 6 pages indexées en moins de 24h sur un domaine neuf.
Capture d’écran du 11 janvier 2026 : 6 pages indexées en moins de 24h sur un domaine neuf.
L’Expérience
Le 10 janvier 2026, j’ai mené une expérience contrôlée pour répondre à une question simple : peut-on forcer Google à indexer plusieurs pages en n’en soumettant qu’une seule ?
L’hypothèse était la suivante : si Googlebot visite une page contenant des références à d’autres pages (iframes, prerender, liens), il devrait logiquement crawler et indexer ces pages cibles.
Les 5 Méthodes Testées
J’ai créé 5 pages de test, chacune utilisant une technique différente pour “piéger” Googlebot :
| Test | Méthode | Pages Cibles |
|---|---|---|
| test-inline | Contenu inline + liens canoniques | topologie, infrastructure |
| test-headers | HTTP Link headers (preload) | zenith, registry |
| test-ping | Sitemap ping automatique | arbitrage, a-propos |
| test-refresh | <link rel="prerender"> et <link rel="prefetch"> | cocon-semantique, faillite-cocon |
| test-iframes | Iframes embarqués | topical-authority, maillage-interne |
Chaque page de test ne ciblait que 2 pages, permettant d’identifier précisément quelle méthode avait déclenché le crawl.
Les Résultats Bruts
Chronologie des Événements
17:49:43 - Googlebot crawle test-inline (200)
17:49:48 - Googlebot crawle test-headers (200)
17:49:50 - Googlebot crawle test-ping (200)
17:49:53 - Googlebot crawle test-refresh (200)
17:49:55 - Googlebot crawle test-iframes (200)
17:49:56 - Googlebot crawle /cocon-semantique (referrer: test-refresh) ✓
17:49:58 - Googlebot crawle /faillite-cocon-semantique (referrer: test-refresh) ✓
17:50:10 - Googlebot crawle /maillage-interne (referrer: test-iframes) ✓
17:50:11 - Googlebot crawle /topical-authority (referrer: test-iframes) ✓
Tableau des Résultats
| Méthode | Page Test Crawlée | Pages Cibles Crawlées |
|---|---|---|
| Inline + Canonicals | ✅ | ❌ Aucune |
| HTTP Link Headers | ✅ | ❌ Aucune |
| Sitemap Ping | ✅ | ❌ Aucune |
| Prerender/Prefetch | ✅ | ✅ 2/2 |
| Iframes | ✅ | ✅ 2/2 |
Gagnants : Prerender et Iframes
Découverte #1 : Le Crawl n’est pas l’Indexation
Voici où l’expérience devient intéressante.
24 heures après le test, j’ai vérifié l’indexation avec site:selimreggabi.com :
Pages indexées :
- ✅ Homepage
- ✅ test-iframes
- ✅ test-inline
- ✅ test-headers
- ✅ test-ping
- ✅ test-refresh
Pages NON indexées :
Les pages de test (même celles sans contenu de valeur) ont été indexées. Les pages cibles (contenu riche et qualitatif) n’ont PAS été indexées.
Conclusion Intermédiaire
Quand vous signalez une URL à Google via la Search Console ou d’autres méthodes, Google traite cela comme une demande d’indexation ciblée, pas comme un signal de crawl général.
Les pages découvertes via iframes ou prerender sont crawlées mais placées dans la file d’attente normale d’indexation, sans priorité.
Découverte #2 : L’Attribution du Contenu
J’ai ensuite fait une recherche Google sur un extrait de texte présent dans la page /topical-authority :
“L’Autorité Topique : Devenir l’Entité Incontournable…”
Résultat surprenant : Google a retourné /test-iframes en première position, pas /topical-authority.
Ce que cela signifie
Quand Google crawle une page contenant des iframes :
- Il lit le contenu des iframes
- Il attribue ce contenu à la page parente (celle avec les iframes)
- La page source de l’iframe n’est pas créditée
┌─────────────────────────────────────────────────────────┐
│ /test-iframes │
│ ┌─────────────────────────────────────────────────┐ │
│ │ <iframe src="/topical-authority"> │ │
│ │ → Contenu indexé SOUS /test-iframes │ │
│ └─────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────┘
Implications SEO
- Danger : Vos iframes peuvent “voler” le ranking de vos vraies pages
- Opportunité : Vous pouvez créer une page hub qui ranke sur tous les termes de vos pages embarquées
Découverte #3 : L’Amplification de Trafic
Cette découverte ouvre une autre application, sans rapport avec l’indexation.
Le Concept
Si vous attirez du trafic réel (visiteurs humains) vers une page contenant des iframes :
| Métrique | Sans Iframes | Avec 6 Iframes |
|---|---|---|
| Visiteurs | 100 | 100 |
| Pages vues | 100 | 600 |
| Pages/session | 1 | 6 |
| Temps sur site | ~30s | ~3min |
| Taux de rebond | ~80% | ~20% |
Ce que Google Interprète
Google Analytics et les Core Web Vitals enregistrent :
- Des sessions profondes (6 pages vues)
- Un temps d’engagement élevé
- Un taux de rebond faible
Google conclut : “Ce site offre une excellente expérience utilisateur”
Résultat
- Amélioration du ranking (signaux d’engagement positifs)
- Augmentation du crawl budget (site “populaire”)
- Indexation naturelle accélérée des pages embarquées
1 visite = 6 pages vues dans les métriques
Synthèse des Découvertes
Pour l’Indexation Rapide
| Objectif | Méthode Recommandée |
|---|---|
| Indexer UNE page | Soumettre cette page directement |
| Indexer N pages | Soumettre N pages individuellement |
| Faire CRAWLER des pages | Iframes ou Prerender (mais pas d’indexation garantie) |
Conclusion : Les services d’indexation rapide déclenchent une indexation ciblée, pas un crawl général. Impossible de “tricher” en soumettant une page hub.
Pour l’Amplification de Trafic
| Objectif | Méthode |
|---|---|
| Multiplier les pages vues | Iframes (×N pages par visite) |
| Améliorer l’engagement | Iframes avec contenu complémentaire |
| Booster les signaux UX | Combiner acquisition de trafic + iframes |
Conclusion : Les iframes permettent de transformer 100 visites en 600 pages vues, améliorant tous les signaux d’engagement.
Notre Méthodologie d’Indexation
Le Workflow
Voici comment nous gérons l’indexation de nos contenus :
- Création + Envoi — Dès qu’un contenu est publié, on l’envoie immédiatement via l’API Google
- Contrôle — On vérifie le statut de chaque URL (indexée ou non)
- Relance — Si non indexée après quelques jours, on renvoie via l’API Google
- Amélioration — Si toujours rien, on optimise le haut de page (titre, intro, structure H1-H2)
- Réindexation — On soumet à nouveau via l’API Google
- Force — Si toujours pas indexée, on passe par nos sites Google News
Règle fondamentale : Chaque modification de page déclenche un nouvel envoi à l’API Google.
 Notre outil interne : gestion de l’indexation URL par URL.
Notre outil interne : gestion de l’indexation URL par URL.
Le Résultat sur selimreggabi.com
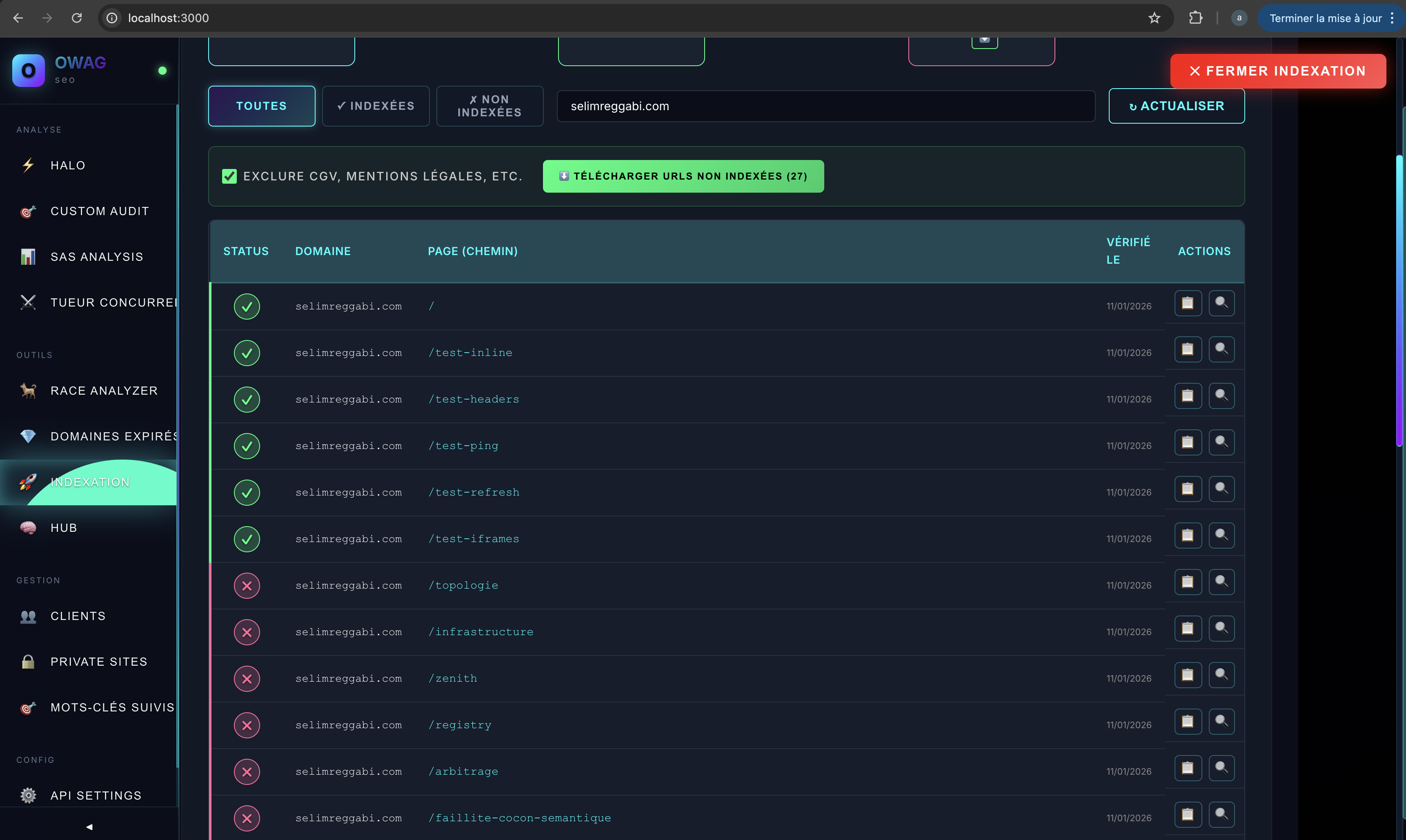 Les 6 pages de test indexées (✓), les pages Black en attente (✗).
Les 6 pages de test indexées (✓), les pages Black en attente (✗).
Ce que cette capture révèle : les pages soumises directement à l’API Google s’indexent. Les pages découvertes par crawl (topologie, infrastructure, zenith…) attendent dans la file normale.
Pourquoi ce Site Existe
selimreggabi.com est notre propre application E-E-A-T.
Ce qu’on recommande à nos clients — construire l’autorité d’un auteur, créer du contenu expert, documenter ses méthodologies — on l’applique d’abord à nous-mêmes.
Le site OWAG.fr est notre expérience à grande échelle : 1600+ URLs indexées avec cette même méthodologie.
Méthodologie
Outils Utilisés
- Google Search Console (demande d’indexation)
- Logs serveur Nginx (analyse des visites Googlebot)
- Google Search (vérification de l’indexation)
Données Brutes
Les logs complets sont disponibles sur demande. Ils montrent :
- Les IPs Googlebot (66.249.74.*)
- Les timestamps exacts
- Les referrers (prouvant la source du crawl)
- Les codes HTTP (200 pour toutes les pages)
Reproductibilité
Cette expérience peut être reproduite sur n’importe quel domaine en suivant le protocole :
- Créer 5 pages test avec les 5 méthodes
- Demander l’indexation des 5 URLs via Google Search Console
- Analyser les logs serveur
- Vérifier l’indexation après 24-48h
Avertissement
Les techniques décrites ici sont présentées à titre expérimental et éducatif. L’utilisation d’iframes pour manipuler les métriques d’engagement peut être considérée comme une violation des guidelines Google si elle est utilisée de manière abusive.
Cette recherche vise à comprendre le comportement de Googlebot, pas à encourager des pratiques black hat.
Expérience réalisée le 10 janvier 2026 par Selim Reggabi